安装k8s
目录
简介
安装 k8s 的记录 -20230606.
安装方式对比
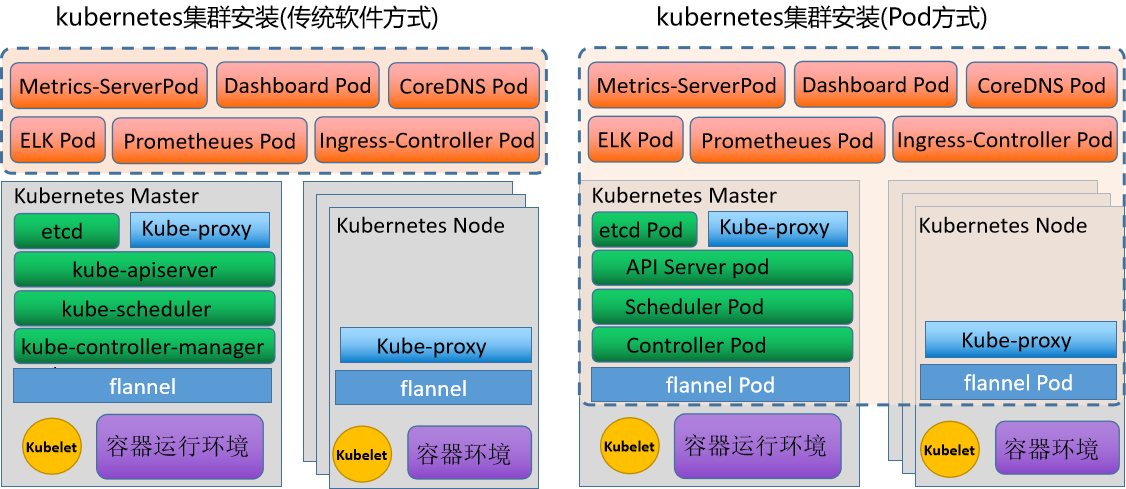
| 安装方式 | 主要区别 |
|---|---|
| 传统方式 | 支撑性软件都是以服务的样式来进行运行,其他的组件以 pod 的方式来运行 |
| Pod 方式 | 除了 kubelet 和容器环境基于服务的方式运行,其他的都以 pod 的方式来运行。 所有的 pod 都被 kubelet 以 manifest(配置清单) 的方式进行统一管理。 由于这种 pod 是基于节点指定目录下的配置文件统一管理的,所有我们将这些 pod 称为静态 pod |
- 传统方式
- 软件源
- 二进制
- ansible 自动化
- pod 方式
- kubeadm
- minikube
kubeadm 安装
基础环境
# 主机名和固定ip
hostnamectl set-hostname master1
reboot
# 防火墙
ufw disable
# 更新一下
apt update -y
apt upgrade -y
# 相关组件
apt install selinux-utils policycoreutils ntp ntpdate htop nethogs nload tree lrzsz iotop iptraf-ng zip unzip ca-certificates curl gnupg build-essential gperf ipset ipvsadm -y
# selinux
vim /etc/selinux/config
SELINUX=disabled
# 时间同步
crontab -e
0 */1 * * * /usr/sbin/ntpdate time1.aliyun.com
# swap
vim /etc/fstab
# 注释掉swap
# 内核
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
# 模块加载
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
# 查看是否加载。出现了就是加载了
lsmod | grep br_netfilter
br_netfilter 22256 0
bridge 151336 1 br_netfilter
lsmod | grep overlay
overlay 151552 0
# 确认为1
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
# ipvs相关
# apt install ipset ipvsadm -y
# 加入
vim /etc/modules-load.d/k8s.conf
overlay
br_netfilter
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack容器相关
# 共享盘,可以忽略
mkdir /mnt/win
mount -t cifs -o username="Everyone" //192.168.2.100/vm_share /mnt/win
cp /mnt/win/* .
# cri-containerd-cni版本会有问题 https://github.com/containerd/containerd/releases
tar Cxzvf /usr/local containerd-1.6.26-linux-amd64.tar.gz
# 试试systemctl daemon-reload
# 如果不行就找到它。放到/etc/systemd/system/下面重新daemon-reload
find / -name containerd.service
vim /etc/systemd/system/containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
#uncomment to enable the experimental sbservice (sandboxed) version of containerd/cri integration
#Environment="ENABLE_CRI_SANDBOXES=sandboxed"
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=infinity
# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this version.
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
vim /etc/containerd/config.toml
# https://github.com/containerd/containerd/issues/4203#issuecomment-651532765
systemdGroup = true
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9"
systemctl enable containerd --now
# 开始安装runc
# 安装c编译器和gperf
# apt install build-essential gperf -y
# 下载https://github.com/opencontainers/runc/releases libseccomp-2.5.4.tar.gz和runc.amd64
tar xf libseccomp-2.5.4.tar.gz
cd libseccomp-2.5.4/
./configure
make && make install
# 验证
find / -name "libseccomp.so"
chmod +x runc.amd64
把这个runc替换掉containerd的sbin里的runc
install -m 755 runc.amd64 /usr/local/sbin/runc
# 下载https://github.com/containernetworking/plugins/releases
mkdir -p /opt/cni/bin
tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.4.0.tgz安装 kubeadm
# 阿里源
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg -o k8s.gpg
gpg --dearmor -o /etc/apt/keyrings/k8s.gpg k8s.gpg
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb [signed-by=/etc/apt/keyrings/k8s.gpg] https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt update -y
apt install -y kubelet kubeadm kubectl
systemctl enable kubelet --nowkubeadm 初始化
kubeadm-init 具体做了什么?
- master 节点启动:
- 当前环境检查,确保当前主机可以部署 kubernetes
- 检查容器引擎,镜像拉取情况
- 生成 kubernetes 对外提供服务所需要的各种私钥以及数字证书
- 证书存放在
/etc/kubernetes/pki的*.key *.cer
- 证书存放在
- 生成 kubernetes 控制组件的 kubeconfig 文件
- 存放在
/etc/kubernetes的*.conf
- 存放在
- 生成 kubernetes 控制组件的 pod 对象需要的 manifest 文件
/etc/kubernetes/manifests下etcd.yamlkube-apiserver.yamlkube-controller-manager.yamlkube-scheduler.yaml
- 为集群控制节点添加相关的标识,不让主节点参与 node 角色工作
- 输入命令
kubectl describe nodes master1看到Taints: node-role.kubernetes.io/master:NoSchedule - 如果没有在 yaml 配置,这可以手动配置
kubectl taint nodes master1 node-role.kubernetes.io/master:NoSchedule
- 输入命令
- 生成集群的统一认证的 token 信息,方便其他节点加入到当前的集群
kube-public有一个configmap叫cluster-info,里面存放着 token 等连接信息
- 进行基于 TLS 的安全引导相关的配置、角色策略、签名请求、自动配置策略
- kubelet 会使用这个
/etc/kubernetes/kubelet.conf配置文件
- kubelet 会使用这个
- 为集群安装 DNS 和 kube-porxy 插件
kube-system空间下面- 如果 cni 网络插件没有弄好,coredns 等几个容器会运行失败
- 当前环境检查,确保当前主机可以部署 kubernetes
- node 节点加入
- 当前环境检查,读取相关集群配置信息
- 容器引擎是否安装,通过
kubectl -n kube-system get cm kubeadm-config -o yaml获取配置
- 容器引擎是否安装,通过
- 获取集群相关数据后启动 kubelet 服务
- 证书信息
/var/lib/kubelet/config.yaml - 启动参数信息
/var/lib/kubelet/kubeadm-flags.env - 启动
- 证书信息
- 获取认证信息后,基于证书方式进行通信
- 当前环境检查,读取相关集群配置信息
[!info] 如果网络有问题, 参考 docker镜像源 从国内先拉取镜像再打上
tag.
kubeadm config images list查看需要用到的镜像kubeadm config images pull可以实现拉取镜像
也可以使用参数 --image-repository 指定国内源. 初始化命令如下:
# 初始化
kubeadm init --image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers' \
--kubernetes-version=v1.28.2 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--apiserver-advertise-address=192.168.2.180 \
--cri-socket unix:///var/run/containerd/containerd.sock可以跳过, 或使用参数 --config config.yml 文件初始化 (kubeadm config print init-defaults)
apiVersion: kubeadm.k8s.io/v1beta3 # 不同版本的api版本不一样
# 节点加入时,认证token授权相关的基本信息。一般在内网比较安全,无需改动
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
# 第一个master节点配置的入口
localAPIEndpoint:
advertiseAddress: 192.168.31.221 # 第一个master的ip
bindPort: 6443
# node节点注册到master集群的通信方式
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: master1 # 第一个master的名字
taints: null
# taints:
# - effect: NoSchedule
# key: node-role.kubernets.io/master
---
# 基本的集群属性信息
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
# 默认没有这个,多个master的时候,这里填keepalived的vip地址
# controlPlaneEndpoint: vip:6443
controllerManager: {}
dns: {}
# kubernetes的数据管理方式
etcd:
local:
dataDir: /var/lib/etcd
# 镜像仓库的配置
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
# kubernetes版本的定制
kubernetesVersion: 1.27.0
# kubernetes的网络基本信息
networking:
dnsDomain: cluster.local
serviceSubnet: "10.96.0.0/12"
podSubnet: "10.244.0.0/16"
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs网络组件
# calico网络插件网段
# 这里应该和kubeadm init --pod-network-cidr=192.168.0.0/16 一致!!!
10.244.0.0/16
# https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.0/manifests/tigera-operator.yamlkubectl 下面这个 yml
# This section includes base Calico installation configuration.
# For more information, see: https://projectcalico.docs.tigera.io/master/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
# Note: The ipPools section cannot be modified post-install.
ipPools:
- blockSize: 26
cidr: 10.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
---
# This section configures the Calico API server.
# For more information, see: https://projectcalico.docs.tigera.io/master/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}启用 ipvs:
kubectl edit configmap kube-proxy -n kube-system
mode: ipvs
kubectl rollout restart daemonset kube-proxy -n kube-system
# 或者一个一个来 kubectl delete po -n kube-system kube-proxy-xxx
# 验证使用了ipvs
kubectl logs kube-proxy-xxx -n kube-system | grep "Using ipvs Proxier"
# 新建service应该会有日志出现
kubectl logs -f -n kube-system -l k8s-app=kube-proxy
# ipvsadm可以帮助我们查看规则
apt install ipvsadm -y
# 查看所有规则
ipvsadm -Ln
# 出来的记录指向多个ip,正好就是service的endpoint里面的ip
ipvsadm -Ln | egrep -A2 'service的cluster-ip'验证安装情况:
# 每个节点都会有一个 pod/calico-node 处于 running 状态
kubectl get all -A -o wide |grep calicoIngress
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.1/deploy/static/provider/cloud/deploy.yamlkubeadm 管理操作
节点重置/扩缩容
- 冻结节点
- 驱离现有资源
- 删除节点
- 清理环境
- 清理遗留信息
- 重启主机
# 冻结
kubectl cordon xxxx-node
# 驱离
# 会先让apiserver删除pod,然后被replicateSet发现后,写入新信息到etcd。然后etcd
kubectl drain xxx-node --force=true --ignore-daemonsets=true --delete-emptydir-data=true
# 删除节点
kubectl delete nodes xxx-node
# 在被移除节点上操作
kubeadm reset
# 清理资源
rm -rf /etc/cni/net.d/*
# master节点要删除 ~/.kube
# 可以跳过,直接到重启部分
tree /etc/kubernetes # 如果有文件就清理
# 重启一下
systemctl restart kubelet docker
# 如果有网络组件,应该清理掉
ifconfig
# 手动关闭网卡,如果是calico也使用一样的方法清理掉
ifconfig flannel.1 down
# 清理ip route
ip route list
ip route del 192.168.1.0/24
# 刷新缓存
ip route flush cache
# 重启一下
reboot
# 重新加入
kubeadm join ...生成加入集群的命令
# 这是node节点的加入命令
kubeadm token create --print-join-command加入新的 master 节点
第一台 master 的 kubeadm 初始化后:
kubeadm init phase upload-certs --upload-certs得到 keykubeadm join ... --control-plane --certificate-key {上面的key}
升级集群
- 确定 k8s 的版本一致
- kubeadm version
- kubectl version
- kubectl get nodes
- 升级 kubeadm 的版本
- 升级
- kubeadm upgrade plan
- kubeadm upgrade apply v 1.28.4
- 升级 kubectl,kubelet 版本
- systemctl daemon-reload
- systemctl restart kubelet
- 升级 worker 节点
- kubectl drain worker-node –ignore-daemonsets
- 升级 kubelet 版本
- systemctl daemon-reload
- systemctl restart kubelet
- kubectl uncordon worker-node
- 重复第一步来验证升级
升级完成 kubeadm 后,可以
kubeadm config images pull来提前拉取镜像
kubekey 安装
基础准备
# 关闭防火墙
systemctl disable firewalld
# 关闭swap
swapon --show
# 在 /etc/sysctl.conf 中添加 vm.swappiness=0
echo "vm.swappiness=0" >> /etc/sysctl.conf
# 如果有内容,那么去 /etc/fstab 注释掉下面的东西
#/swap.img none swap sw 0 0
# 重启电脑验证
swapon --show
# 关闭selinux
apt install selinux-utils
# 查看输出
getenforce
# 安装依赖
apt install socat conntrack ebtables ipset -y安装
# 安装kubekey工具
export KKZONE=cn
curl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.1 sh -
chmod +x kk
# 创建配置
./kk create config
# 编辑配置文件
vim config-sample.yaml
# 开始安装
./kk create cluster -f config-sample.yaml --with-kubesphere
# 确定没问题就yes
# 如果上面没有--with-kubesphere,手动安装的话
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
# 检查安装日志
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
# 验证所有pod都起来了
kubectl get pod --all-namespaces
# 检查控制台端口,默认30880
kubectl get svc/ks-console -n kubesphere-system
# 访问nodeport
ip:30880 admin/P@88w0rd集群管理
# 从集群创建配置文件
./kk create config --from-cluster
# 或
./kk create config -f kubeconfig配置文件
# 添加节点
# 编辑配置
./kk add nodes -f sample.yaml
# 删除节点
# 界面停止调度
# 编辑配置
./kk delete node <nodeName> -f config-sample.yaml配置文件 demo
apiVersion: kubekey.kubesphere.io/v1alpha1
kind: Cluster
metadata:
name: sample
spec:
hosts:
- {name: master, address: 192.168.10.71, internalAddress: 192.168.10.71, user: root, password: 密码}
- {name: node1, address: 192.168.10.72, internalAddress: 192.168.10.72, user: root, password: 密码}
- {name: node2, address: 192.168.10.73, internalAddress: 192.168.10.73, user: root, password: 密码}
roleGroups:
etcd:
- master
master:
- master
worker:
- node1
- node2
controlPlaneEndpoint:
##Internal loadbalancer for apiservers
#internalLoadbalancer: haproxy
domain: lb.kubesphere.local
address: ""
port: 6443
kubernetes:
version: v1.21.5
clusterName: cluster.local
network:
plugin: calico
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
registry:
registryMirrors: ["https://u7hlore1.mirror.aliyuncs.com"]
insecureRegistries: []
privateRegistry: ""
addons: []