k8s组件剖析
简介
k8s 的组件学习记录
主要组件如下:
- 容器技术
- Api-server: 提供 api 接口作为主要入口
- Etcd: 存储配置和状态信息
- Controller Manager: 控制器, 管理 Replication,Deployment 等等
- Scheduler: 调度分发应用程序
- kubelet: 管理容器的启动和停止, 健康状态
- kube-proxy: 每个节点上的代理,转发的实现
- CoreDNS: 内部的 dns 解析
- 网络组件: 联通节点, 容器网络
- Ingress Controller: 提供对外的入口. 承接 Http, https 流量
容器
- k8s 通过 CRI 规范来进行实际的编排操作.
- docker 操作 Containerd
- Containerd 操作符合 OCI 标准的容器运行时. 采用 runc 为默认容器运行时.
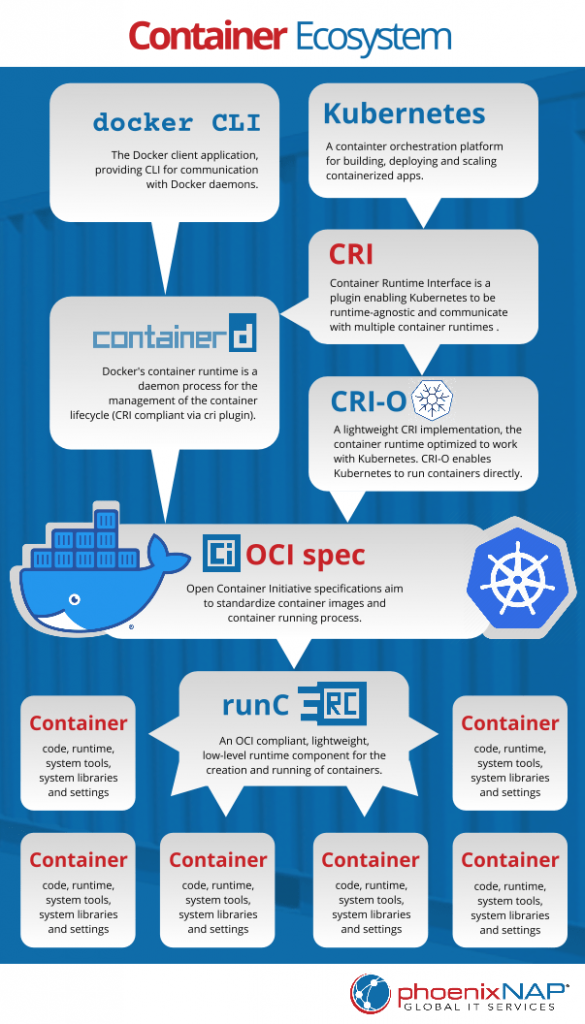
同上图:
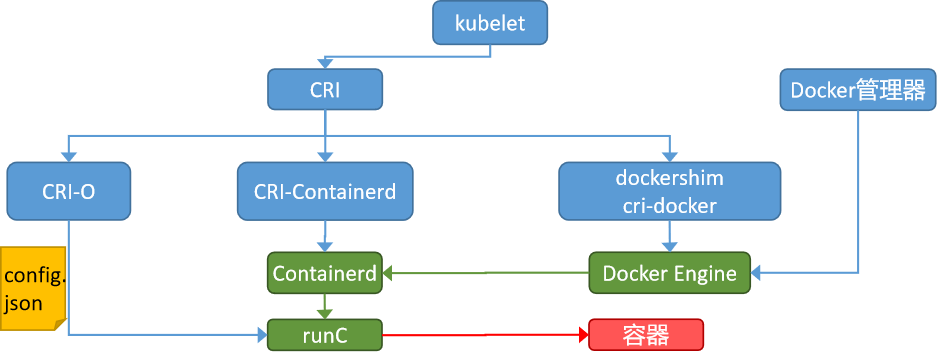
题外话 docker 其实从 1.12 版本开始, 已经可以通过 组件方式 支持 CRI 标准. 但是 Containerd 直接集成 CRI 到了自己内部, 这样就少了 docker 和 CRI 组件两个环节. 同时 Containerd 不像 docker 属于公司, 所以 k8s 从 1.24 版本开始切换到了 Containerd.
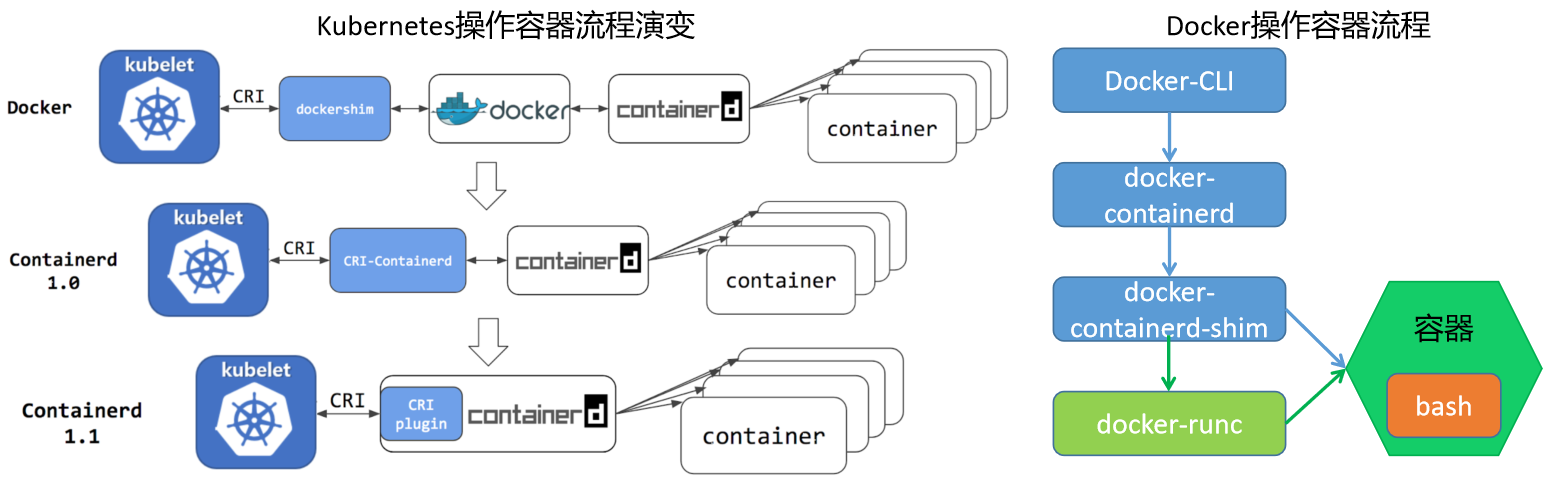
master 节点
- api-server:处理 api 操作,所有组件都通过 api-server
- controller:对集群状态处理。自动容器修复,水平扩展
- scheduler:完成调度操作。根据用户提交的的数据,调度到指定节点
- etcd:分布式存储。所有元信息存储
node 节点
- kubelet:通过 api-server 拿到状态,调用 containner-runtime 启动容器
- storage-plugin 和 network-plugin 完成对应操作
- kube-proxy 服务于 service。通过 iptables 实现功能
api-server 传递流程
- user 提交到 api-server
- api-server 写入到 etcd
- scheduler 通过 watch 到的信息,进行调度决策
- scheduler 调用 api-server,说应该怎么调度
- api-server 写入到 etcd
- kubelet 通过 watch 到的信息,调用 container-runtime 进行部署
kubelet
- 定期从所监听的数据源获取期望状态,调整自身到期望状态
- 容器的健康检查与健康检查策略
- 容器监控。向 master 提供报告信息
kube-proxy (iptables/IPVS)
kube-proxy 监听的对象如下:
- service
- endpoint/endpointslices
- node
kube-proxy 会监听 api-Server 的资源变化,配置 nodePort 和本地的 iptables/IPVS。pod 与 pod、外部请求与 pod 之间的通信,都会经过 iptables/IPVS。于是完成了流量转发和负载均衡。
外部 SLB 负载均衡,其实也是把请求转发给 nodePort。只不过每个 worker 节点上通过虚拟网卡,绑定了很多的 ip。这些 ip 对应着一个个 pod 实例。
因此负载均衡直接请求 worker 节点的特定网卡 ip 地址,即可请求到对应 pod。同时云商做了优化,性能比传统方式好。
在创建一个 service 后,通常会创建一个 endpoint 对象 (除了 headless,headless 是在 dns 搞了一个别名)。
client 访问 service 的时候有 2 种方式。
- 通过域名。也就是 coreDNS 解析出来地址
- 通过 ip 地址访问。这是一个虚拟的 ip 地址,请求在转发到 kube-proxy 后,通过本地的 iptables 规则转发到对应的 pod
服务拓扑就需要监听 node 信息,实现一个服务可以指定流量是被优先路由到一个和客户端在同一个 Node 或者在同一可用区域的端点。
ipvs 是 iptables 是使用了 ipset 拓展。它和默认方式否是基于 Netfilter 实现的。默认是做防火墙,而 ipvs 是做负载均衡的。
scheduler 调度
调度过程
- 提交到 api-server
- controller 验证以后,api-server 中变成 pending、同时 nodeName 为空
- scheduler 发现这个空 nodeName 的 pod 后,开始调度算法、打分。写入 nodeName
- kubelet 在 watch 到以后,开始制定调度细节
- 最后状态为 running
QoS 调度打分
默认优先级
- Guaranteed- 高保障:cpu 和 memory 的 request=limit,其他资源可不等
- Burstable- 中,弹性:cpu 和 memory 的 request!=limit
- BestEffort- 低,尽力而为:所有资源必须都不填
调度表现:
- 一定先满足 request 请求
- 如果 –cpu-manager-policy=static,且高保障 Guaranteed。会绑核, 避免 cpu 一会儿给 a 服务使用, 一会儿切换到 b 服务.
- memory 会根据 QoS 级别进行打分,低优先级 BestEffort 被调走
影响调度
ResourceQuota限制命名空间的 cpu, 内存, pods 总数pod亲和,pod与node亲和,pod容忍污点会影响调度PriorityClass可以配置在 pod 上, 默认没有启用
pv 和 pvc
- 提交创建 pvc 对象
- csi-provisioner 给 watch 到,根据 pvc 中的 storage-class 和其他信息,调用 csi-plugin1。于是在云存储中创建真正的存储,于是有了 pv 对象
- pv 对象被 pv-controller 观察到,于是把 pv 和 pvc 对象绑定
- 提交的 pod 被调度到 node,kubelet 使用通过 csi-plugin2 挂载对应的 pv 到容器,再启动容器
如果 pvc 没有使用 name, label, storage-class 等方式指定, 会启用自动匹配机制. DefaultStorageClass 将 PVC 与 PV 会自动绑定,根据 PVC 的大小、权限等进行自动匹配后绑定的。

# 查看默认的storageclass
kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
local (default) openebs.io/local Delete WaitForFirstConsumer false 558d- VolumeReclaimPolicy
- Delete 如果 pvc 被删除,pv 立即删除,磁盘空间释放
- Retain 如果 pvc 被删除,pv 不会被删除,需要手动去清理
- VolumeBindingMode
- Immediate 适合大部分共享存储,默认
- WaitForFirstConsumer 等确定 pod 分配到某个节点后,在那个节点再创建 pv
- 如果你要是
网络
安装了网络组件以后,kubectl get nodes 才回是 ready 状态
默认地址段
pod
pod 网络默认地址为 10.244.0.0/16,集群节点都可以 curl ip:port 访问到.
service
service 网络默认地址为 10.96.0.0/12
本地容器网络
网络模型
docker 默认网络模型: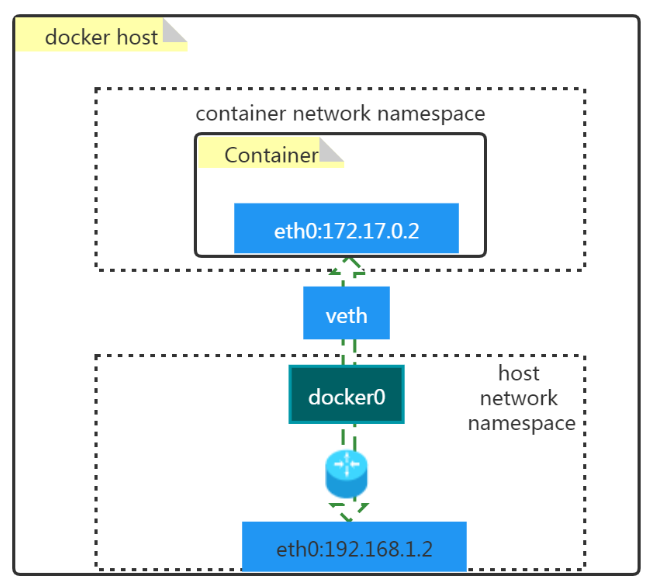
ifconfig 命令可以看到 docker0 和 veth73abaa8 这样的
- docker0
- 是一个二层网络设备,即网桥
- 通过网桥可以将 Linux 支持的不同的端口连接起来
- 实现类交换机多对多的通信
- veth pair
- 虚拟以太网(Ethernet)设备
- 成对出现,用于解决网络命名空间之间的隔离
- 一端连接 Container network namespace,另一端连接 host network namespace
所有网络模型
- 默认
--network bridgeBridge 桥接子网络 --network host共享宿主机网络接口--network none仅本机 lo 通信
--network container:c1(容器名称或容器 ID)并不是一种类型,而是加入目标相同的网络
docker network ls 查看已有的网络模型, docker network inspect minikube 查看 minikube 网络细节
外部通信
容器访问外网: 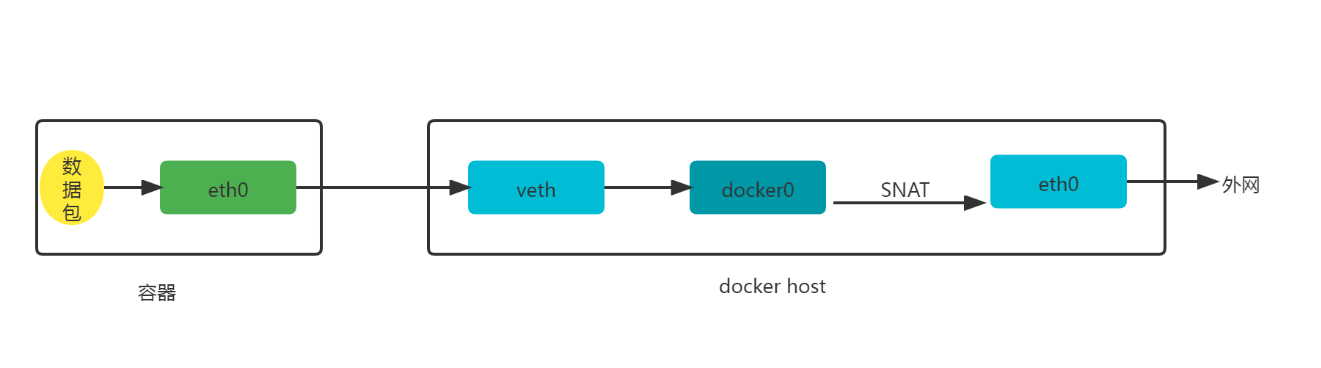
外网访问容器: 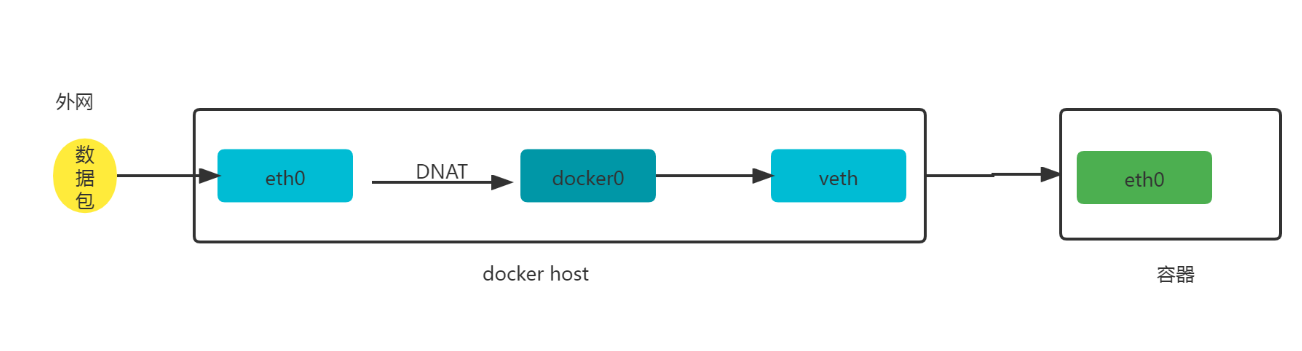
跨主机网络
所有方案
docker 原生方案
- overlay
- 基于 VXLAN 封装实现 Docker 原生 overlay 网络
- macvlan
- Docker 主机网卡接口逻辑上分为多个子接口,每个子接口标识一个 VLAN,容器接口直接连接 Docker Host
- 网卡接口
- 通过路由策略转发到另一台 Docker Host
第三方方案
- Flannel
- 支持 UDP 和 VLAN 封装传输方式
- Weave
- 支持 UDP 和 VXLAN
- OpenvSwitch
- 支持 VXLAN 和 GRE 协议
- Calico
- 支持 BGP 协议和 IPIP 隧道
- 每台宿主机作为虚拟路由,通过 BGP 协议实现不同主机容器间通信。
k8s 的 CNI 方案有 3 种,主要用 flannel 和 calico。他们 2 个都支持 3 种。
- flannel 是普遍使用。小规模
- calico 主打网络策略。限制策略。大规模性能更好
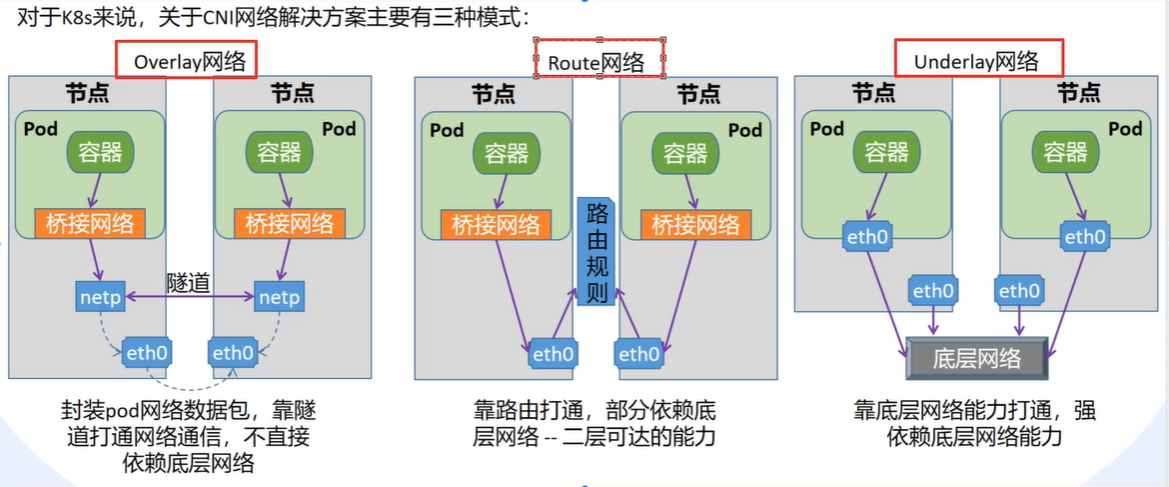
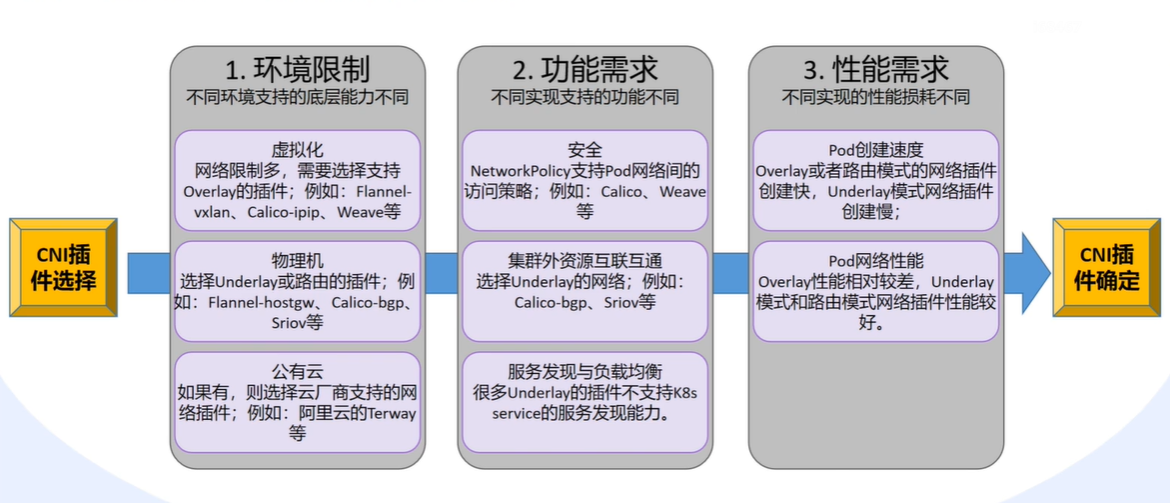
方案选择:
Flannel
docker 容器无法跨主机通信, Flannel 分配子网网段, 然后记录在 etcd 中实现通信.
安装也不难。安装并启动 etcd 以后设置一个 key,flannel 配置文件加入这个 key,配置好并启动。可以参考这里 搭建Flannel
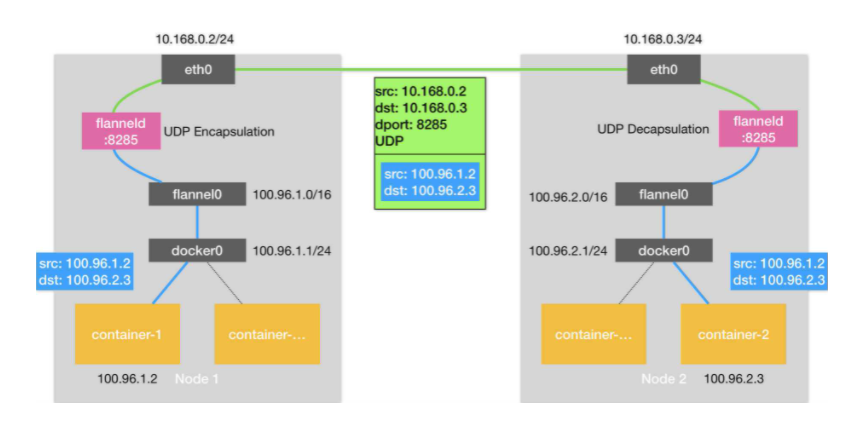
- 数据从源容器中发出后,经由所在主机的 docker0 虚拟网卡转发到 flannel0 虚拟网卡,这是个 P2P 的虚拟网卡,flanneld 服务监听在网卡的另外一端。
- Flannel 通过 Etcd 服务维护了一张节点间的路由表,该张表里保存了各个节点主机的子网网段信息。
- 源主机的 flanneld 服务将原本的数据内容 UDP 封装后根据自己的路由表投递给目的节点的 flanneld 服务,数据到达以后被解包,然后直接进入目的节点的 flannel0 虚拟网卡,然后被转发到目的主机的 docker0 虚拟网卡,最后就像本机容器通信一样的由 docker0 路由到达目标容器。
k8s 中的 flannel:
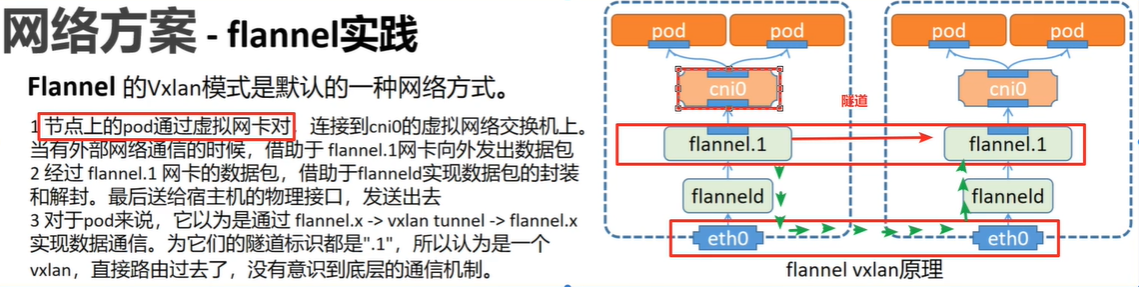
相关命令:
- 查看 svc 模式
cat kube-flannel.yml - 查看 Vxlan 数据包流转
ip route list | grep flannel路由表关系ip neigh | grep flannel数据包转发关系bridge fdb show flannel.1 |grep flannel.1隧道转发关系- 说明:
ip neigh | grep flannel看到对应 ip 网段转发的网卡,在bridge fdb show flannel.1 |grep flannel.1找到对应的网卡和主机 ip 对应规则。ifconfig 中的 vethxxxx 就是 pod 内的网卡地址
calico
ingress
流量方案对比
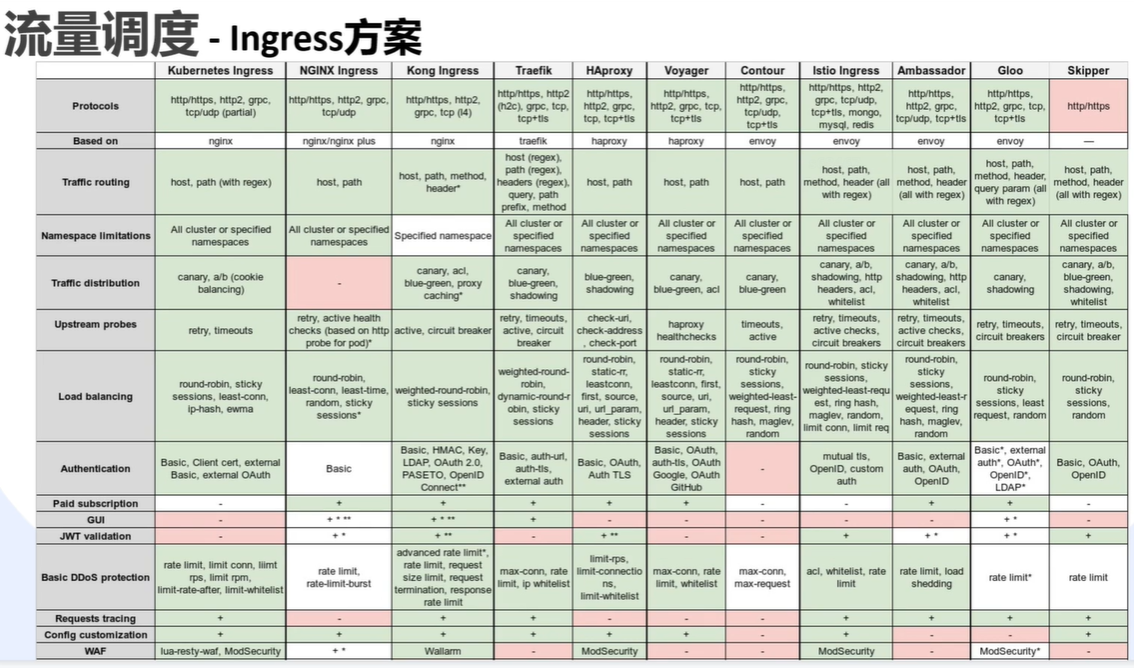
externaltrafficpolicy
- cluster:跨节点转发,负载更好。但多了一次 snat。获取源 ip 可能会有问题,性能差一点。并且会让上层的负载均衡权重失效。
- local:永远不会跨节点转发。不丢失源 ip。性能好一点。如果 3 个节点,但是只有 2 个 nginx 提供服务,会导致 node3 无法转发。如果发版切换到了 node3,上层负载均衡无法感知。需要控制器 Cloud Controller Management(简称:CCM) 感应 endpoint 变化。通知给 ELB。ELB 其实就是 load-balance。
- 云厂商就是用的 local 模式 + load-balance 。负载均衡和权重在外部做了,可以跨节点转发,又不会失去源 ip。云厂商自己也有配套的 CCE
阿里云 使用Service对外暴露应用 自建K8s集群如何部署CCM组件 ccm 的开源地址 其他相关资料 externalTrafficPolicy为Local的服务重启时如何保证zero downtime - 知乎 参考 externaltrafficpolicy的有关问题说明 - 紫色飞猪 - 博客园
#todo/笔记 自己搭建一个测试?
deployment 控制器
- 判断是否是新的版本,选择更新 replicaset 或者整个 deployment 资源
- 更新会保存到到 etcd
- 由 scheduler 进行调度分配
- kubelet 进行 watch,执行具体的调整动作
如果调整整个 deployment 资源,那么会新建一个 replicas 来替换。回滚也是一样
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deploy
namespace: default
labels:
app: example
annotations:
deployment.kubernetes.io/revision: "1"
description: "完整 Deployment 示例"
spec:
replicas: 3 # 副本数
revisionHistoryLimit: 10 # 保留多少历史 ReplicaSet
progressDeadlineSeconds: 600 # 超时判定
paused: false # 是否暂停 rollout
minReadySeconds: 0 # Pod 需要 ready 保持多久
strategy:
type: RollingUpdate # RollingUpdate 或 Recreate
rollingUpdate:
maxUnavailable: 1 # 滚动更新时最大不可用
maxSurge: 1 # 滚动更新时最大新增
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
annotations:
checksum/config: "123456" # 用于触发滚动更新
spec:
serviceAccountName: default
automountServiceAccountToken: true
hostNetwork: false
hostPID: false
hostIPC: false
nodeSelector: # 节点选择器
disktype: ssd
nodeName: "" # 指定调度到某个节点(一般不用)
schedulerName: default-scheduler
priorityClassName: "" # Pod 优先级
runtimeClassName: "" # 运行时类型,例如 kata
dnsPolicy: ClusterFirst
dnsConfig:
nameservers:
- 8.8.8.8
searches:
- svc.cluster.local
options:
- name: ndots
value: "2"
restartPolicy: Always # Deployment 固定是 Always(不能改)
hostAliases: # Hosts 重写
- ip: "127.0.0.1"
hostnames:
- "my.local"
imagePullSecrets:
- name: myregistry-secret
securityContext:
runAsUser: 1000
runAsGroup: 1000
fsGroup: 2000
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
terminationGracePeriodSeconds: 30
affinity: # 亲和性设置
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: important
topologyKey: "kubernetes.io/hostname"
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app: example
topologyKey: "kubernetes.io/hostname"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
tolerationSeconds: 3600
topologySpreadConstraints: # 跨节点分布控制
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: example
initContainers:
- name: init-myservice
image: busybox:latest
command:
- sh
- -c
- "sleep 5"
volumeMounts:
- name: data
mountPath: /data
containers:
- name: example
image: nginx:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c"]
args: ["nginx -g 'daemon off;'"]
workingDir: /app
ports:
- containerPort: 80
name: http
protocol: TCP
env:
- name: ENV
value: production
- name: FROM_CONFIGMAP
valueFrom:
configMapKeyRef:
name: app-config
key: app.json
envFrom:
- configMapRef:
name: global-config
- secretRef:
name: global-secret
resources: # 资源限制
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "100m"
memory: "128Mi"
securityContext:
privileged: false
readOnlyRootFilesystem: false
allowPrivilegeEscalation: false
capabilities:
add: ["NET_ADMIN"]
drop: ["ALL"]
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 3
successThreshold: 1
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 5
startupProbe:
httpGet:
path: /
port: 80
failureThreshold: 30
periodSeconds: 10
lifecycle:
postStart:
exec:
command: ["sh", "-c", "echo postStart"]
preStop:
exec:
command: ["sh", "-c", "sleep 10"]
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumes:
- name: data
emptyDir: {}
- name: config
configMap:
name: app-config
- name: secret-volume
secret:
secretName: my-secretPod
pod 详解
- 顺序启动 2 个容器。一个是 init 容器,然后是程序容器
- 程序容器中有一个 infra 或者说 pause 容器
- 因为容器被 linux namespace 和 cgroups 隔离,所以让容器都加入 infra 的网络空间。所以 mac 地址,ip,网络设备都是一样的。
- pause 启用 pid 命名空间,开启 init 进程。比 init 容器更早创建出来
- 启动失败:back-off delay (10 s, 20 s, 40 s, …),最长 5 分钟。一旦启动成功了 10 分钟,就会重置 delay 时间
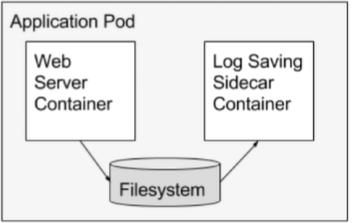
设计模式 sidecar
作用:
- 可以收集日志。docker 应用写入到 volume,然后通过 initContainer 来收集日志。
- 访问外部集群的时候,通过它可以进行一个反向代理。这样就不需要修改容器代码。访问一个地址即可实现。例如 zk,我们是一个集群。通过一个统一的 proxy 代理,即可让所有 docker 复用这一配置。
- 适配器。可以做到类似 nginx 的 rewrite 域名转发。访问/a 的时候请求转到应用 docker 的/b 路径。
stateful 有状态应用
重要特性
- rollout 重启是按照顺序重建,0,1,2 这样
- 同名的 pod 永远不会同时存在。所以如果应用只允许单个 pod 运行,部署和 rollout 都不需要担心会有问题
通过 mysql 的实例学习 运行一个有状态的应用程序 | Kubernetes
service 控制器
- service 创建后,创建一个同名 endpoint
- endpoint controller 筛选符合的 pod,绑定到 endpoint 对象
- service 通过 cluster-ip 对外提供 endpoint 内的信息
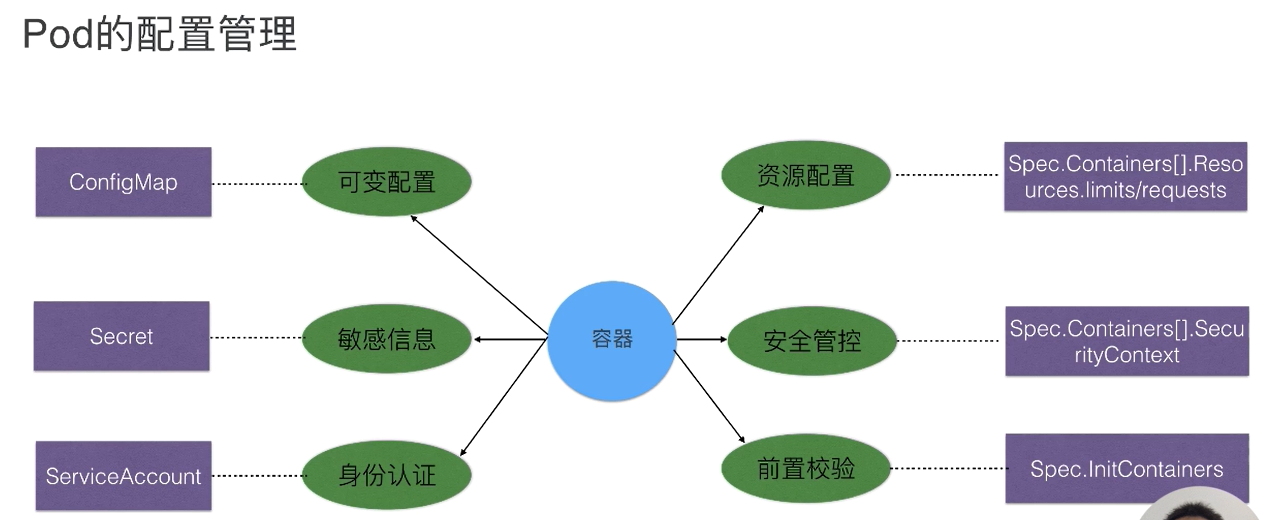
k8s 配置管理
存储
存储挂载
- 同个 volumn 或者多个 volumn 都可以按照下面的方式挂在到不同路径
- mountPath 是主机路径
- subPath 是 volumn 路径。避免每个 volumn 的路径/文件名重复造成的冲突
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
volumeMounts:
- name: my-volume
mountPath: /data/data1
subPath: data1/file.txt
- name: my-volume
mountPath: /data/data2
subPath: data2/file.txt
volumes:
- name: my-volume
persistentVolumeClaim:
name: my-pvc存储方案
如果不用第三方,不用 nfs 之类的。就用 ceph
coredns
- 可以使用
nslookup来解析 ip 或者域名 - 每个容器的
/etc/resolv.conf都有 coredns 的配置信息 - 在初始化集群的时候,会有一个 dnsDoimain 是
cluster.local,所以 svc ,pod 等资源的结尾是资源名称xxx-svc.命名空间default.资源类型svc.cluster.local
第三方组件
监控
- cadvisor 监控容器的资源使用率,但是 k8s 已经内置了 google/cadvisor
- KSM 收集集群相关的内容,需要自己部署 kubernetes/kube-state-metrics: Add-on agent to generate and expose cluster-level metrics.
- 收集使用信息,计算成本 Kubecost Documentation
KEDA 缩放
使用 crontab 的方式定时扩缩容